
 10 months ago
10 months ago 
Das Ende von Teil 5 hinterlässt einen bitteren Nachgeschmack. Aber dass eine Distribution eventuell nicht richtig namentlich identifiziert werden kann, ist jedoch nur ein Symptom. Das eigentliche Problem liegt woanders und stellt die wahre Herausforderung dar:
Kompatibilität
Es gibt so viele Eventualitäten, die zu bedenken sind. Man müsste als Entwickler jede Hardware und jedes Betriebssystem zur Verfügung haben, um perfekte Software zu programmieren. Hier ein Beispiel:
Neofetch liest auf meinem Raspberry Pi das Modell als Host aus und nicht den Hostnamen. Das zeigt, dass jemand das Programm auf einem Pi getestet und Anpassungen speziell für diese Hardware vorgenommen hat. Die Information liegt übrigens in /proc/device-tree/model.
Alle Eventualitäten können wir nicht abbilden, das würde den Rahmen komplett sprengen. Dadurch wird jedoch aufgezeigt, welcher Aufwand hinter der Software steckt, die wir nutzen.
Was bedeutet das für unseren Code?
Wenn die Datei /proc/device-tree/model existiert soll Host den Inhalt von model ausgeben. Ja, das geht und ist sehr komplex. Hier kommt aber wieder das Problem der Hardware-Verfügbarkeit ins Spiel. Selbst, wenn wir diese Funktion einbauen, werdet ihr kein Ergebnis sehen, denn ihr besitzt vielleicht keinen Raspberry Pi.
Wir kommen hier nicht weiter!
Das mag jetzt eigenartig klingen und nicht zielführend sein, aber das im letzten Punkt angeführte Beispiel verfolgen wir jetzt nicht weiter. Ihr werdet oft an den Punkt kommen, an dem ihr an etwas arbeitet, aber es nicht möglich ist, eine bestimmte Funktionalität einzubauen. Damit das Programm aber trotzdem läuft, müssen trotzdem weitere Teile programmiert werden. Oder etwas genauer gesprochen:
Das Feature ist in Arbeit und wird später implementiert. Hier ist es eine gute Praxis, dies zu dokumentieren. Wir könnten einen Notizzettel anlegen, auf dem steht:
Zukünftige Features:
- Raspberry Pi Kompatibilität
- Echtzeit Daten auslesen
- IP-Adresse anzeigen
- Swap?
- Festplattenspeicher?
Anmerkung: Aus dieser kleinen List könnt Ihr herauslesen, das wir definitiv nicht aufhören wenn unsere 1zu1-Kopie von neofetch fertig ist.
Rückmeldungen
So muss Community sein! Ich bin dankbar für eure Rückmeldungen. Es geht hier ja nicht um Likes, sondern um die Vermittlung von Wissen. Natürlich freut es mich auch, dass es euch gefällt. Wir müssen aber auch nacharbeiten.
So funktioniert das Auslesen des Users wie befürchtet nicht einwandfrei. Um das auszubügeln, gehen wir so vor:
Wir ändern die Variable user zu:
user = os.environ["USER"]Ihr könnt gerne den folgenden Code ausführen. Der Output zeigt alle Keys und Values an, die os.environ zu bieten hat. Wir werden diese Methode benötigen, wenn es darum geht, die Desktopumgebung auszulesen.
import os print(os.environ)Außerdem
Mir ist im Nachhinein eingefallen, dass es ja DistroSea gibt. Somit wird es sehr einfach werden, Eigenheiten der beliebtesten Distributionen aufzuspüren.
Schritt für Schritt
Wir haben bereits gelernt, wie man den Benutzer, den Host und das Betriebssystem auslesen kann. Nach sorgfältiger Abwägung habe ich entschieden, dass wir nicht immer die Labels so ausarbeiten werden, wie sie in neofetch aufgelistet sind. Stattdessen werden wir sie nach Schwierigkeitsgrad bearbeiten. Das hat den Vorteil einer stetigen und nicht sprunghaften Progression. Der Nachteil ist, dass wir in unserer main.py hin- und her-scrollen müssen. Das bedeutet auch, Codeblöcke zwischen anderen einzufügen. Daher ist es wichtig, übersichtlichen Code zu schreiben. Das beinhaltet jedoch auch eine wertvolle Lektion: Auch wenn Python sehr flexibel ist, kann man nicht einfach ein neues Feature irgendwo in den Code schreiben. Versucht das ruhig mal, der Interpreter wird euch sagen, dass etwas nicht stimmt. Außerdem gilt es, Redundanzen zu vermeiden, um Übersichtlichkeit zu gewährleisten. Was das bedeutet, lernt ihr jetzt.
Aber jetzt weiter mit unserem Programm
Wie ihr seht, wird es immer wichtiger, ausführlich zu erklären. Deshalb werden die Artikel wahrscheinlich auch länger. Manchmal ist es auch notwendig, den übernächsten Schritt zuerst zu erläutern, um einen ganzheitlichen Eindruck zu vermitteln.
Unser neofetch-tk sieht im Moment so aus:
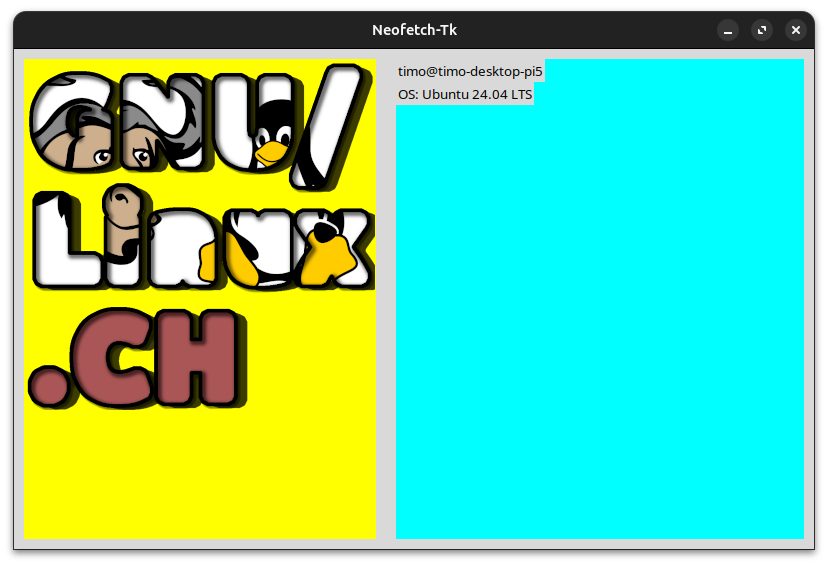
Der nächste Punkt auf der Liste ist "Host:". Es sollte relativ offensichtlich sein, was wir jetzt tun müssen: Wir nutzen das, was wir bereits haben.
host_label = tk.Label(stat_frame,text=f"Host: {hostname}") host_label.pack(anchor=tk.NW)Hier wird die Kernel-Version angegeben. Dafür müssen wir das Modul platform importieren. Wir fügen zur Liste `import platform` hinzu.
import platformAnschließend erstellen wir eine neue Variable. Die Methode ".release()" liest nur den Kernel-Release aus.
kernel_release = platform.release()Unter unserem Host-Label fügen wir ein neues Label hinzu.
kernel_label = tk.Label(stat_frame,text=f"Kernel: {kernel_release}") kernel_label.pack(anchor=tk.NW)Der ganze Code
## Teil 6 ### import tkinter as tk from PIL import Image, ImageTk import os import socket import distro import platform user = os.environ["USER"] hostname = socket.gethostname() os_release_pretty = distro.name(pretty=True) kernel_release = platform.release() # Erstelle das Hauptfenster root = tk.Tk() root.title("Neofetch-Tk") root.geometry("800x500") distro_logo = tk.PhotoImage(file="images/test.png") # Einen Frame Zeichen logo_frame = tk.Frame(root,background="yellow") logo_frame.pack(fill="both",expand=False,side='left',padx=10,pady=10) # Distro-Logo-Label distro_icon = tk.Label(logo_frame,text="DISTRO LOGO",image=distro_logo,background="yellow") distro_icon.pack(anchor=tk.NW) # Einen Frame Zeichen stat_frame = tk.Frame(root,background="cyan") stat_frame.pack(fill="both",expand=True,side='left',padx=10,pady=10) # Label mit Text USER@HOST user_host_label = tk.Label(stat_frame,text=f"{user}@{hostname}") user_host_label.pack(anchor=tk.NW) # Label mit Text OS: os_label = tk.Label(stat_frame,text=f"OS: {os_release_pretty}") os_label.pack(anchor=tk.NW) # Label mit Text Host: host_label = tk.Label(stat_frame,text=f"Host: {hostname}") host_label.pack(anchor=tk.NW) # Label mit Text Kernel: kernel_label = tk.Label(stat_frame,text=f"Kernel: {kernel_release}") kernel_label.pack(anchor=tk.NW) # Starte die Hauptschleife root.mainloop()Die erste Funktion
Bisher haben wir den Code einfach heruntergeschrieben, und durch den mainloop wird er bis zum Schließen des Fensters immer wieder neu eingelesen und direkt ausgeführt. Aber was, wenn wir einen bestimmten Teil des Codes nur zu einem bestimmten Zeitpunkt ausführen wollen? Hier kommen Funktionen ins Spiel. Stellen euch eine Funktion wie eine Schublade vor, in der wir wichtige Informationen für alle Eventualitäten abgelegt haben. Wenn wir eine Information benötigen, öffnen wir die Schublade und nehmen, was wir brauchen.
Wir schreiben eine Funktion und nennen sie "Wie heiße ich?".
Auf Python-Deutsch:
wie_heisse_ich()Die Klammern zeigen an: Hier ist Inhalt, und dieser wird ausgeführt. Wir haben aber noch gar keinen Inhalt; den müssen wir noch definieren.
def wie_heisse_ich(): name = "Ester" return name print(f"Ich heiße {wie_heisse_ich()}!")Wir haben also in unserer Schublade abgelegt, dass wir Ester heißen. Das Konzept der ersten und zweiten Zeile lässt sich gut erschließen:
- def sagt aus, dass hier etwas definiert wird. Es folgt der Name der Funktion, und der Doppelpunkt sagt: Ab jetzt kommt der Inhalt. Die dritte Zeile ist nicht immer notwendig, in diesem Fall aber von Relevanz.
Die Dritte Zeile ist nicht immer notwendig in die hier aber von relevanz.
- return sagt aus, dass, wenn wie_heisse_ich() aufgerufen wird, die Variable name ausgegeben werden soll.
Das geht auch
def wie_heisse_ich(): name = "Ester" print(f"Ich heiße {name}!") wie_heisse_ich()Noch ein Beispiel
Das nächste Beispiel zeigt, wie wir eine Funktion immer und immer wieder im Code mit einem anderen Ergebniss einbauen können.
def das_ist_eine_funktion(x,y): addition = x + x print(addition) subtraktion = x - y print(subtraktion) multiplikation = x * y print(multiplikation) division = x / y print(division) x = 3 y = 2 das_ist_eine_funktion(x,y) x = 33 y = 22 das_ist_eine_funktion(x,y)Alles nur geklaut?
Ich lese unheimlich gerne Code und natürlich nutze ich Suchmaschinen und Stack-Overflow, um Antworten auf meine Code-Fragen zu finden. Manchmal muss ich aber schmunzeln, denn gerade, wenn es um das Auslesen von System-Daten geht, fällt mir immer öfter komplett unveränderten Python-Code in Projekten von dieser Website enthält auf:
Klar, einige sind besser im Programmieren, andere schlechter, aber wir kochen alle doch nur mit Wasser.
Oder sollte ich eher sagen: "Wir Copy&Pasten alle doch nur aus dem Internet"?
Egal, jedenfalls brauchen wir den Code von dieser Seite für unser nächstes Label und auch folgende.
Das Memory-Label (Oder: noch mehr Mathematik)
import psutil def get_size(bytes, suffix="B"): """ Scale bytes to its proper format e.g: 1253656 => '1.20MB' 1253656678 => '1.17GB' """ factor = 1024 for unit in ["", "K", "M", "G", "T", "P"]: if bytes < factor: return f"{bytes:.2f}{unit}{suffix}" bytes /= factor svmem = psutil.virtual_memory() print(f"Total: {get_size(svmem.total)}") print(f"Used: {get_size(svmem.used)}")Was ihr hier lest, habe ich aus dem Code der besagten Seite zusammen-geschnippelt, damit wir uns auf das konzentrieren können, was gerade wichtig ist.
Aber was ist ein psutil? Und was ist dieses get_size-Ding?
Die Ausgabe sieht so aus (Bei mir):
Es handelt sich um den Arbeitsspeicher meines Pi5s. Genauer gesagt, die Speicher-Größe und der genutzte Speicher.
Aber wie funktioniert das?
- get_size(svmem.total) soll ausgegeben werden
- svmem.total gibt den Maschinen-Code als Bytes in die Funktion, zusammen mit dem Anhang B
- Ein Byte hat die Größe 1024 (Faktor)
Mit for loops hatten wir bisher noch keine Berührung, mal gucken, ob wir diese Methode noch brauchen. Ich denke, ich lasse das als Zwischenspiel in den nächsten Teil einfließen. Weiter im Text.
- Der for loop läuft für den Wert von svmem.total über Bytes, Kilobyte, Megabyte, Gigabyte usw.
- Wenn die Anzahl der Bytes kleiner als 1024, wird die Größe zurückgegeben
- Ist die Anzahl größer, wird sie durch 1024 geteilt
Ok, das ist für Anfänger wahrscheinlich etwas heftig. Ich erkläre es mal einfacher.
Geben wir das ganze doch mal ohne die Funktion aus:
print(f"Total: {svmem.total)")Das Ergebnis ist: Total: 4178722816
Jetzt nehmen wir uns einen Taschenrechner und teilen immer wieder durch 1024 bis und die Zahl bekannt vorkommt.

Wenn ihr wieder nach oben scrollt sehr ihr das die Zahl zum Verwechseln ähnlich dem Gesamtspeicher meines Pis aus sieht.
Außerdem wird noch auf zwei Stellen nach dem Komma gekürzt und die richtige Einheit angegeben.
Ich hoffe, das ist einigermaßen verständlich, aber es ist leider das womit wir arbeiten müssen.
Wie bauen wir das alles in unseren Code ein?
Zunächst müssen wir psutil installieren:
sudo apt install python3-psutilWir importieren psutil und fügen die Funktion direkt unter der Importliste ein.
def get_size(bytes, suffix="B"): """ Scale bytes to its proper format e.g: 1253656 => '1.20MB' 1253656678 => '1.17GB' """ factor = 1024 for unit in ["", "K", "M", "G", "T", "P"]: if bytes < factor: return f"{bytes:.2f}{unit}{suffix}" bytes /= factorZu unserer Variable-Liste fügen wir svmem hinzu
user = os.environ["USER"] hostname = socket.gethostname() os_release_pretty = distro.name(pretty=True) kernel_release = platform.release() svmem = psutil.virtual_memory()Unten erstellen wir das Label mem_label.
mem_label = tk.Label(stat_frame,text=f"Memory: {(get_size(svmem.used))}/{get_size(svmem.total)}") mem_label.pack(anchor=tk.NW)
Der ganze Code
## Teil 6 ### import tkinter as tk from PIL import Image, ImageTk import os import socket import distro import platform import psutil def get_size(bytes, suffix="B"): """ Scale bytes to its proper format e.g: 1253656 => '1.20MB' 1253656678 => '1.17GB' """ factor = 1024 for unit in ["", "K", "M", "G", "T", "P"]: if bytes < factor: return f"{bytes:.2f}{unit}{suffix}" bytes /= factor user = os.environ["USER"] hostname = socket.gethostname() os_release_pretty = distro.name(pretty=True) kernel_release = platform.release() svmem = psutil.virtual_memory() # Erstelle das Hauptfenster root = tk.Tk() root.title("Neofetch-Tk") root.geometry("800x500") distro_logo = tk.PhotoImage(file="images/test.png") # Einen Frame Zeichen logo_frame = tk.Frame(root,background="yellow") logo_frame.pack(fill="both",expand=False,side='left',padx=10,pady=10) # Distro-Logo-Label distro_icon = tk.Label(logo_frame,text="DISTRO LOGO",image=distro_logo,background="yellow") distro_icon.pack(anchor=tk.NW) # Einen Frame Zeichen stat_frame = tk.Frame(root,background="cyan") stat_frame.pack(fill="both",expand=True,side='left',padx=10,pady=10) # Label mit Text USER@HOST user_host_label = tk.Label(stat_frame,text=f"{user}@{hostname}") user_host_label.pack(anchor=tk.NW) # Label mit Text OS: os_label = tk.Label(stat_frame,text=f"OS: {os_release_pretty}") os_label.pack(anchor=tk.NW) host_label = tk.Label(stat_frame,text=f"Host: {hostname}") host_label.pack(anchor=tk.NW) kernel_label = tk.Label(stat_frame,text=f"Kernel: {kernel_release}") kernel_label.pack(anchor=tk.NW) mem_label = tk.Label(stat_frame,text=f"Memory: {(get_size(svmem.used))}/{get_size(svmem.total)}") mem_label.pack(anchor=tk.NW) # Starte die Hauptschleife root.mainloop()Ich weiß, das war extrem viel, es musste aber sein. Bis nächste Woche.
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.





