
 8 months ago
8 months ago 
In dieser Woche sind mir zwei Berichte über den Weg gelaufen, die mich nachdenklich gestimmt haben, weshalb ich zum Wochenende darüber schreibe. Beginnen möchte ich mit einer neuen Anwendung namens Alpaca, die die Verwendung von verschiedenen Large Language Models (LLM) auf dem lokalen Rechner ermöglicht. Das könnte für alle interessant sein, die ihre KI-Anfragen nicht in die Wolken schicken möchten.
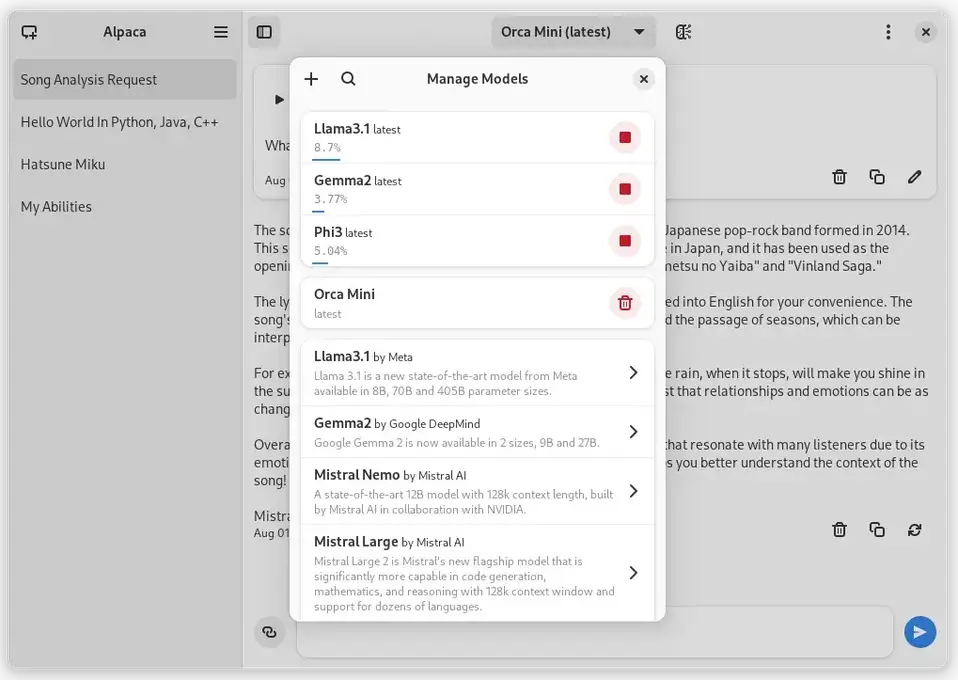
Alpaca bietet eine grafische Anwendung für das CLI-Werkzeug Ollama, welches den Betrieb von einigen LLMs auf dem lokalen Computer ermöglicht. Wer sich nicht mit der Installation und der Terminalbedienung von Ollama herumschlagen möchte, erhält mit Alpaca eine bequeme Option. Ollama bietet drölfzig LLMs zum Herunterladen an. Hier seht ihr eine kleine Auswahl mit Grössenangaben:
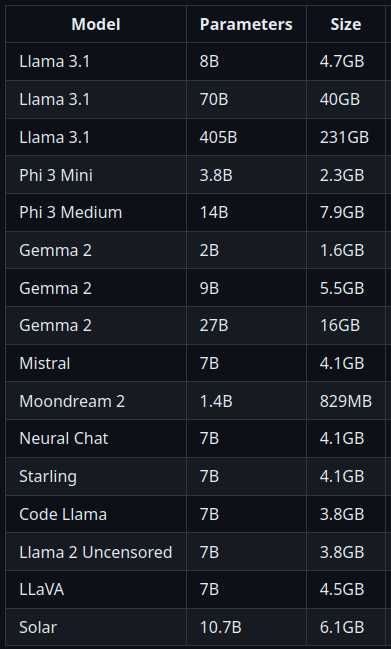
Falls ihr das Ausprobieren möchtet, solltet ihr unbedingt auf die Modellgrösse achten, da diese vollständig in den Arbeitsspeicher geladen werden. Wenn ihr weniger als 16 GB RAM habt, würde ich gar nicht erst damit anfangen.
Die Bedienung von Alpaca ist selbsterklärend: gewünschte LLMs herunterladen und den Chat beginnen. Im linken Panel seht ihr eure Anfragen, während rechts der Prompt und die Antworten stehen. Ich habe die Anwendung nicht installiert und getestet, sondern lediglich aufgrund von anderen Artikeln darüber geschrieben. Deshalb kann ich nichts zur Qualität der angebotenen Modelle sagen.
So viel zum Alpaca; jetzt komme ich zu den Hunden, bzw. zum Golden Retriever. Wer regelmässig den Podcast Minkorrekt hört, kann an dieser Stelle den Browser schliessen und sich in den Liegestuhl legen.
In der Folge 308 hat Reini über die Studie "AI models collapse when trained on recursively generated data" von Yarin Gal (et al.), die am 24. Juli 2024 bei Nature publiziert wurde.
Unwichtige Nebenbemerkung: Die Nature-Seite ist bei mir in Firefox völlig kaputt. Nur in der Leseansicht kann ich damit etwas anfangen.
Übersetzt lautet der Titel der Studie: "KI-Modelle kollabieren bei rekursiv generierten Daten"
Und noch ein Einschub: Für die Übersetzung des Titels habe ich die parzielle Übersetzungsfunktion von Firefox 129 verwendet. Eine sehr willkommende Funktion des Browsers.
In der Studie wurde unter anderem untersucht, wie sich die Generierung von Hundebildern nach mehreren Lernläufen verändert. Das Ergebnis einer Generierung wurde in mehreren Modell-Generationen wieder als Eingabe für das Training des Modells verwendet. Das führte dazu, dass nach wenigen Generationen (Trainingsläufen) alle Hunde als Golden Retriever dargestellt wurden.

Golden Retriever sind beliebte Hunde, weshalb man auch überproportional viele Bilder dieser Hunderasse im Internet findet. Trainiert man ein KI-Modell mit Bildern aus dem Internet, so wirkt sich der Bias (Tendenz) schnell darauf aus, was das Modell für einen Hund hält. Die Studie hat weitere Untersuchungen mit Texten gemacht. Auch dort ergab sich nach wenigen Trainingsgenerationen das Inzest-Problem.
Führt man das Experiment in dieser Art durch: 100 % der KI-Ausgaben werden für den nächsten Lauf als Eingabe verwendet, schlägt der Bias schnell auf die Ergebnisse durch. Doch es geht noch schlimmer. Nach weiteren Trainingsläufen bleibt es nicht beim Golden Retriever; die typischen Merkmale dieser Hunderasse werden so weit verstärkt, dass nach weiteren Generationen nur noch ein Bild-Brei übrigbleibt. Da ich auf die Ergebnisse der Studie nicht zugreifen kann (danke, Nature), habe ich versucht, das Ergebnis zu simulieren:

Hinweis: das ist eine Simulation
Die Studie zeigt in drastischer Weise auf, was passiert, wenn das Ergebnis von KI-Resultaten wieder als Eingabe für KI-Modelle verwendet wird: nach wenigen Generationen kollabieren die Modelle und liefern nur noch Unsinn. Was in der Studie verstärkt wurde, findet im realen Internet nicht so statt. Doch die Entwicklung geht in diese Richtung. Leute verwenden KI-Tools, um Ergebnisse zu produzieren. Diese Ergebnisse landen wiederum im Internet, worauf sie für das Training der nächsten Versionen der Modelle verwendet werden.
Schon heute haben Firmen wie Google, Apple, Microsoft, Meta und OpenAI Probleme, saubere Trainingsdaten zu finden, weil das Internet bereits abgegrast wurde. Die Firmen kaufen sich in geschützte Inhalte ein: Reddit, Verlage, ... Je mehr KI-generierte Inhalte zurück ins Internet gespült werden, desto inzestuöser werden die Ausgaben der Modelle. Es ist ein sich selbst verstärkender Kreislauf, der nicht nur negative Auswirkungen auf die Leistung der Chatbots und Bild-Generatoren hat, sondern auch auf die gesamte Qualität des Internets.
Fazit
Es gibt Spezialanwendungen im KI-Umfeld, die mit qualitativ hochwertigen und themenbezogen Daten trainiert werden. Zum Beispiel im medizinischen Bereich, um Krankheiten zu entdecken. Das ist gut und nützlich. Wenn es um GPTs (Generative pre-trained transformers) geht, sehe ich eher schwarz. Bei den GPTs geht es um Masse, nicht um Klasse. Vielleicht solltet ihr Alpaca nicht verwenden.
Mein Blick in die Glaskugel sagt, dass sich die GPTs innerhalb der nächsten 5 Jahre selbst zerstören werden. Bis dahin könnt ihr noch Produkte kaufen, die ein KI-Label haben :)

Quellen:
https://flathub.org/apps/com.jeffser.Alpaca
https://github.com/ollama/ollama?tab=readme-ov-file
https://minkorrekt.de/mi308-ramschkirchen/
https://www.nature.com/articles/s41586-024-07566-y
https://www.friend.com/product.html
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.





